HOT CHIPS is one of the semiconductor industry’s leading conferences on high-performance microprocessors and related integrated circuits. This year, the latest technologies and products were introduced and presented by engineers and chip designers from famous corporations and national laboratories. The conference was held virtually from August 22nd to 24th.
It had several sessions including CPUs, data processors, machine learning platforms, and etc. There were many innovations and technical improvements introduced in high-quality presentations.
This year, several top-level corporations brought their new CPUs. Here, I am going to share some topics I am interested in and my impressions.
1. Intel Alder Lake
Alder Lake is the newest generation of Intel Core processors. The core design is totally different from the past. It uses two different cores with different architectures, P-core and E-core, to achieve the performance hybrid.


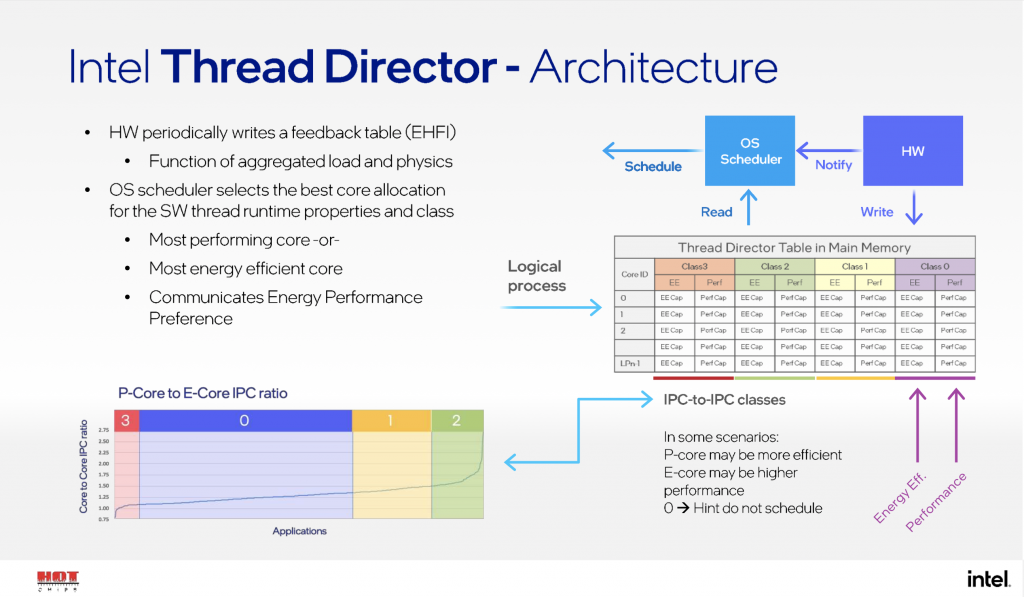
P-core delivers higher performance on single and lightly threaded scalable applications, while E-core provides better throughput on multi-threaded applications. For the scheduling, Intel uses the Thread Director to put the right workload on the right core at the right time. Based on the IPC differences between P-core and E-core, applications are classified into 4 classes. The information on energy efficiency and performance is periodically written into the EHFI table. Then the OS scheduler selects the best core allocation. The Thread Direct architecture is shown as follows.
2. AMD Zen3
Compared to Zen2, the new generation achieves 19% IPC improvement, which is awesome. The figure shows major changes in Zen3.
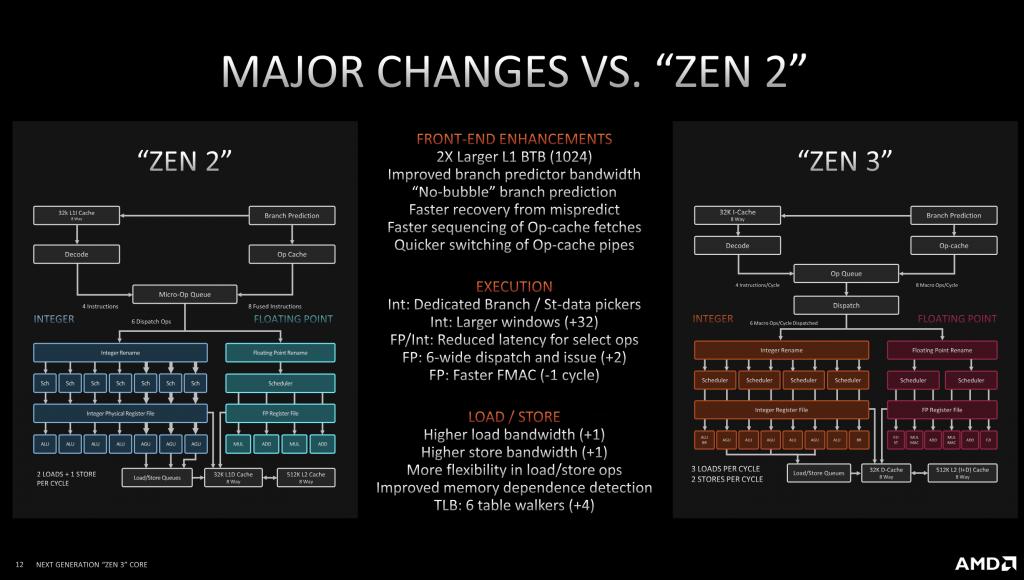
The most interesting part for me is the Zen3 cache hierarchy. Although the total size of the L3 is not changed, the direct accessibility per core becomes twice, which brings the reduction in effective memory latency. The outstanding misses of L2 and L3 are also amazing. Besides, their 3D V-cache technology makes the L3 192MB, which is a surprising capacity.


3. IBM Telum
The new IBM Z system is quite different from Z15, especially the cache hierarchy. Each core has a private 32MB L2 cache, which is 8 times larger than the L2 cache in Z15. However, in Telum, there are no physical L3 and L4 caches, instead, IBM uses L2 to generate virtual L3 and L4 caches. This inspiring design greatly saves chip areas and latencies of L3 and L4, while still remains their functions, and further improves cache size per core. With such implementation, the system can achieve over 40% per socket performance growth.

4. Intel Xeon Sapphire Rapids
Recently, modular architecture has become popular in processor design. This is because a smaller die size can bring better yield in the chip fabrication. Thus, Sapphire Rapids uses EMIB technology to achieve a multi-tile design. The acceleration engine in each tile is one important part. It includes data streaming, quick assist technology, and dynamic load balancer, and supports common-mode tasks offload.

In addition, the shared LLC is also increased this time, and the HBM with 2 modes (flat or caching) are mentioned.
There are still many brilliant presentations that I cannot introduce to them all. For example, Samsung’s HBM2-PIM, the chiplet and 3D packaging, and etc. From this conference, I have learned a great number of inspiring ideas and technologies. I am impressed by their creations and efforts in achieving improvements. These new architectures and ideas show me popular trends in chip design fields and will help a lot for my own research.
A welcome party was held at the end of June to celebrate the assignment of new B3 students.
Thanks to a fascinating web service, we still had a great time although the party could not be held face-to-face. We are looking forward to seeing the B3 students play an active role in this lab in the future!
We took a group photo of B4 members and professors for the graduation album!
The weather cleared up just in time before the rainy season, and we got some great shots!
What a day!

Hi, this is Sasaki, a master-course student.
IPDPS2021(35th IEEE International Parallel & Distributed Processing Symposium) was held from May 17th to 21st.
Although the name is “Parallel & Distributed Processing,” its scope is so large, from architecture to cloud computing and neural networks, and it is like a “mini-SC.”
The conference had been scheduled to be held in Portland, US, but was held online like last year.
In a workshop, iWAPT2021(The 16th International Workshop on Automatic Performance Tuning), I made a presentation about the file I/O characteristics of heterogeneous HPC systems and the necessity of auto-tuning.
The details of the presentation are shown as follows.

IPDPS2022 will be held in Lyon, France if it can be held face-to-face.
I hope to be able to go abroad soon!
Hello there, I’m Aoyagi, a 4th-year undergraduate (B4) student.
As a part of ‘skill map’ training for new B4 students, each person gets one jetson Xavier.
Xavier, Xavier, Xavier♪♪
Have you ever heard Xavier before♪♪
That’s the same spelling as that Xavier♪♪
What a surprise, Xavier♪♪
Although this Xavier, the Nvidia’s missionary, has the almost same size as Rasberry pi, it has a GPU inside.
Xavier is definitely much powerful than its appearance.
After installing the OS, we tried to let it learn the MNIST dataset.
Xavier says, ‘No sweat!’ And his fan was not even rotated.
Okay there. It seems like we have to write some tough programs to make it sweats!

Hi, I am Furuhata a.k.a “shimo”.
A type of container environment, Singularity, is installed on the Lab’s servers.
(I spent the whole golden week (the long vacation in Japan) for it.)
Singularity is often compared to The “BLUE WHALE”.
The reason our lab chose the Singularity instead of docker is that Singularity can be ran without root permission.
Also, since Singularity is the container designed for HPC, we can actually use it in the supercomputer systems.
I strongly hope that Singularity could enhance labmate’s productivity and manage servers easier.
The father/mother of Singularity -> https://sylabs.io/
![]()
Hello, this is Liu from Takizawa Lab.
2021 IEEE Symposium on Low-Power and High-Speed Chips and Systems (COOL Chips 24) was held during April 14-16.
Because of the COVID-19, the COOL Chips 24 was held as a virtual conference.
I made a presentation in the Poster Session. Here are the details of the poster.

At the end of March, we had a farewell party for the year 2020.
It’s a pity that we couldn’t meet face-to-face for the last time due to the new coronavirus, but it was nice to have a good time with everyone in the lab as usual!
In April, new members will be added to our lab, and we will start our new life at Takizawa Lab.
We wish the seniors all the best in their new positions and the further development of our laboratory!
Hello, this is Kaneko.
Recently, a new server was installed in our laboratory. This server will be equipped with high-end FPGAs and GPUs, and will be used for research.

Due to the coronavirus, the graduation ceremony of Tohoku University was canceled. Instead, a small one was held in our lab.

Hope all alumni could enjoy their job and study in the future.
Also, don’t forget to come back again and keep communications with our labmates!