The Cyberscience Center was founded as a national supercomputer center hosted by Tohoku University in 1969. Since then, the Center has been installing high-end computing systems and providing them to researchers and students nationwide in Japan. In addition to the role of a national inter-university joint usage/research center for high performance computing, the Center is responsible for cyber-infrastructure of the University.
In 2020, we installed a new supercomputer, AOBA.
AOBA System Information
The world's first system of the second-generation SX-Aurora
TSUBASA
Professor Kozo Fujii (Tokyo University of Science)
Professor Satoru Yamamoto (Tohoku University)
Our Recent Presentations
Research Projects at the Cyberscience Center
We focus on the design and development of high-performance supercomputing systems and their applications. Since it is necessary to well understand and exploit the parallelism of the underlying hardware for high performance, we are developing programming models and supportive tools to facilitate the parallel programming and code optimization. In addition, as supercomputer systems are becoming larger and more complicated, its power consumption and dependability become critical design constraints of supercomputers. Therefore, we are designing/architecting the next generation supercomputers with high power efficiency and dependability.
Application Development
Working together with application
developers to achieve high performance.
Machine Learning for HPC
Performance-aware programming assisted
by machine learning.
HPC Programming Framework
Application development is a teamwork
of different kinds of programmers.
QA for Combinatorial Problems
Making a good use of emerging
devices for
HPC.
Heterogeneous Computing
Programming with assigning right tasks
to right
processors.
Task Mapping and Scheduling
Intelligent resource management for
highly efficient computing.
Tsunami Inundation Simulation
Predicting damage from a tsunami immediately after the earthquake.
Memory Architecture Design
Integrating large and fast memories into a single system.
Code Optimization and Tuning
Making application codes suitable for a specific architecture.
* These projects are partially supported by MEXT Next Generation High-Performance Computing Infrastructures and Applications R&D Program, entitled "R&D of A Quantum-Annealing-Assisted Next Generation HPC Infrastructure and its Applications."
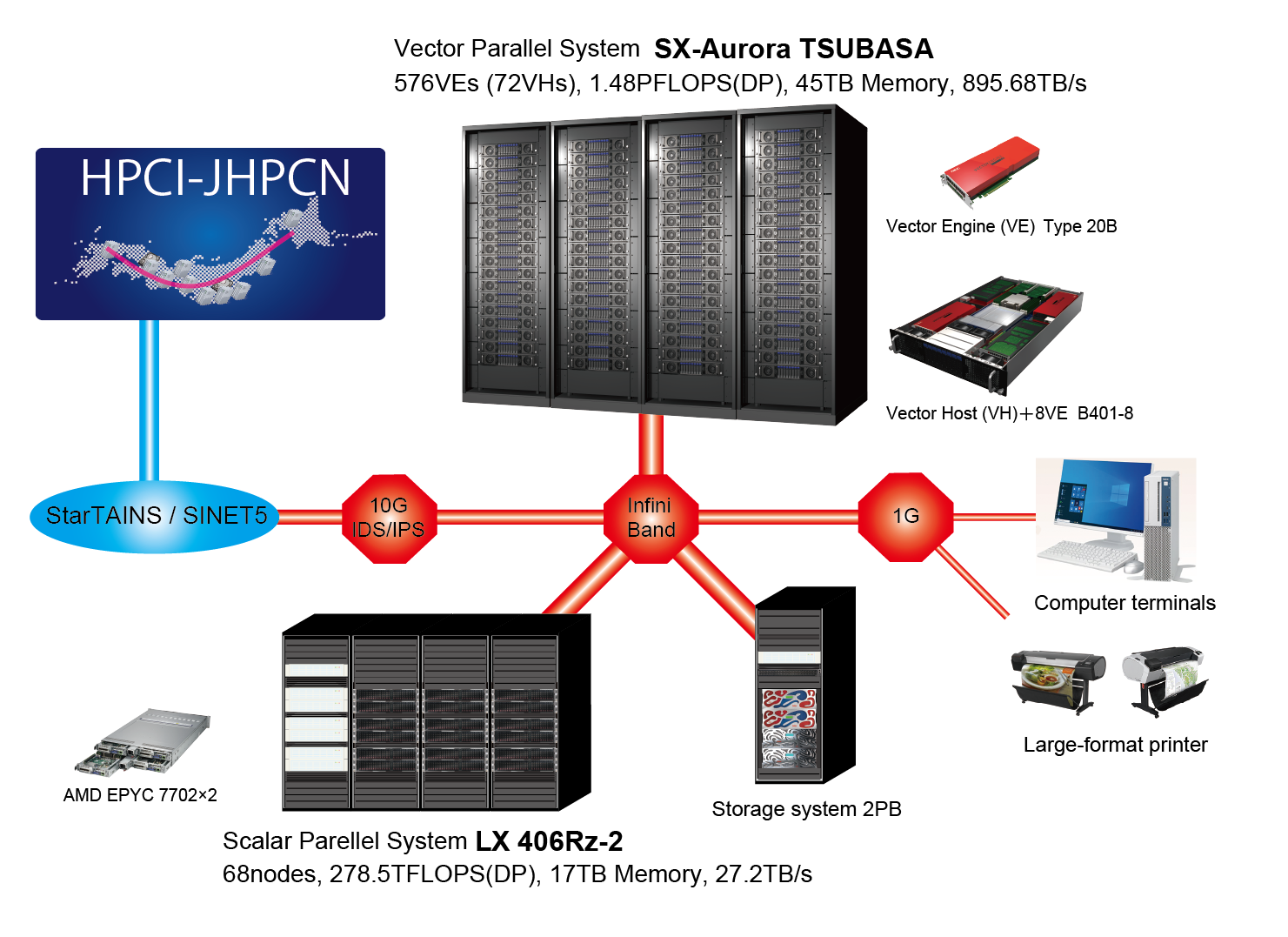
System Configuration
Supercomputer AOBA consists of two subsystems, AOBA-A
and AOBA-B.
AOBA-A is a 72-node system of NEC SX-Aurora TSUBASA, while AOBA-B is a 68-node
system of NEC LX 406Rz-2. Both of the two subsystems use AMD EYPC 7702 processors.
Besides,
each node of AOBA-A is equipped with 8 Vector Engines Type 20B.
Total performance: 1.78 Pflop/s
Total memory bandwidth: 924 TB/s
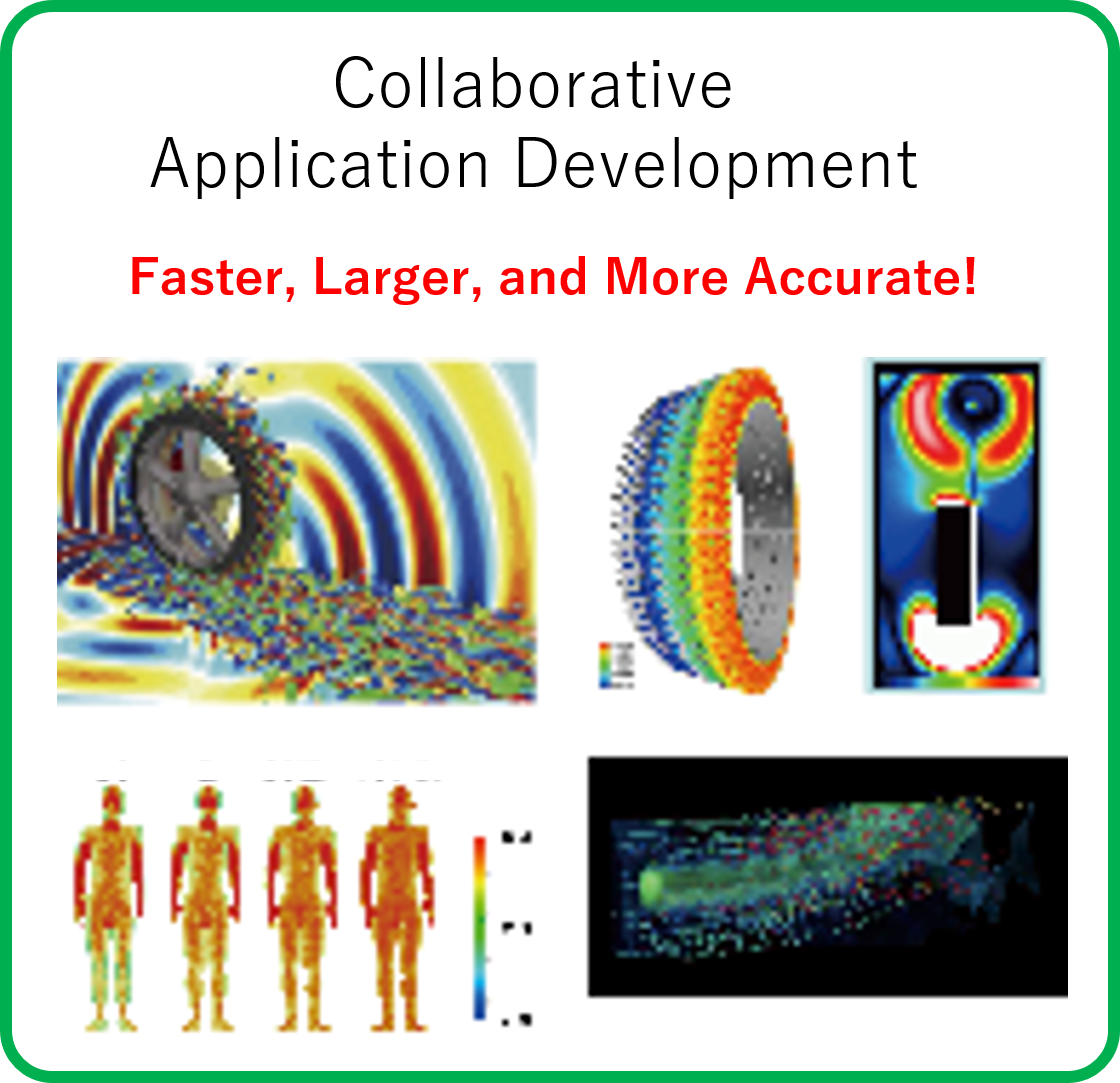
Application Development
We are working together with application developers to
achieve high performance.
We have a lot of joint-research projects with application developers in various
research areas. As a major supercomputing center, the Cyberscience Center
has made
outstanding contributions to various research fields,
such as Airplane and Turbine simulations for engineering,
Tsunami inundation and flood simulations for disaster prevention and reduction, and
heat stroke risk simulation for public health.
Code Optimization by Machine Learning
Can ML replace a "Superprogrammer"?
Conventionally, high performance computing (HPC) applications
are optimized for their target computing systems based
on experiences of programmers. The program optimization
often needs to select an appropriate implementation from
multiple candidates, and the implementation selection has
usually been made in a try and error fashion. Thus, there
is a demand for automating the implementation selection.
Recently, it is extensively reported that machine learning
models can successfully replace various tasks that have empirically
been done by experts. Therefore, machine learning
becomes a promising approach to the automation of program
optimization.
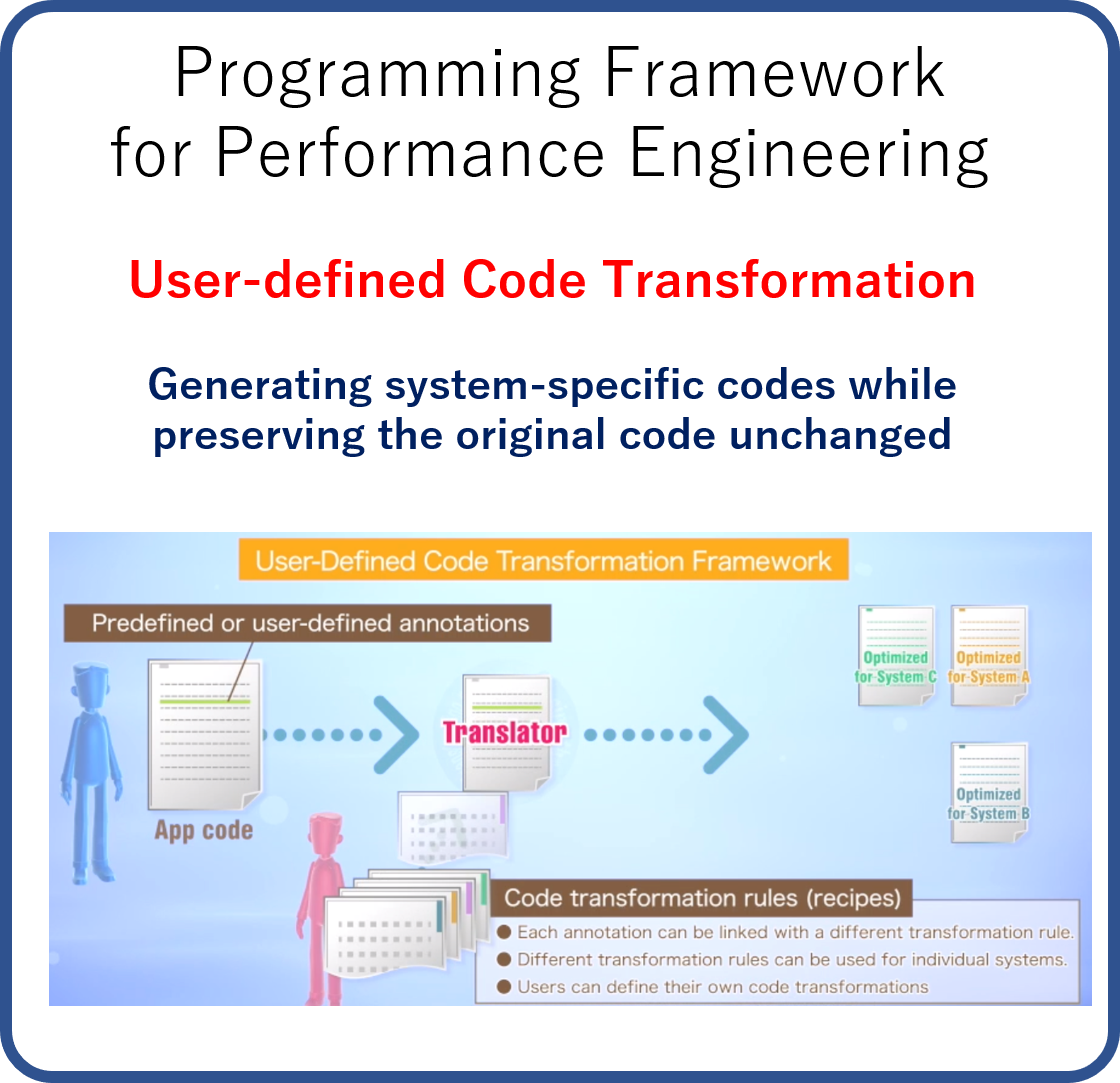
Code Transformation for Performance Tuning
A key to success is effective collabotion between
application developers and performance engineers.
System‐aware code optimizations often make it difficult for programmers to maintain
HPC application codes. On the other
side, system‐aware code optimizations are mandatory to exploit the performance of
target HPC systems. To achieve both
high maintainability and high performance, we develop the Xevolver framework that
provides an easy
way to express system‐aware code
optimizations as user‐defined code transformation rules. Those rules can be defined
separately from HPC application
codes. As a result, an HPC application code is converted into its optimized version
for a particular target system just
before the compilation, and standard HPC programmers do not usually need to maintain
the optimized version that could be
complicated and difficult‐to‐maintain.
HPC and Quantum Computing
How can the emerging devices help HPC? How can HPC help
the emerging devices?
The effects that problem formulation and embedding have on the performance of
a quantum
annealer (QA) are not well
studied. Thus we investigate these effects, determine methods through
which performance can be
maximized, and investigate the
interplay between them. We select scheduling problems for our evaluation.
Scheduling is one of the most ubiquitous
types of problems in optimization and has applications in many fields. The standard
form of these problems is finding an
assignment of tasks to resources that satisfies problem constraints; however,
real world applications require domain
specific variants. In this work, we select the standard n×m job-shop
scheduling problem (JSP) to evaluate
the performance of QA.
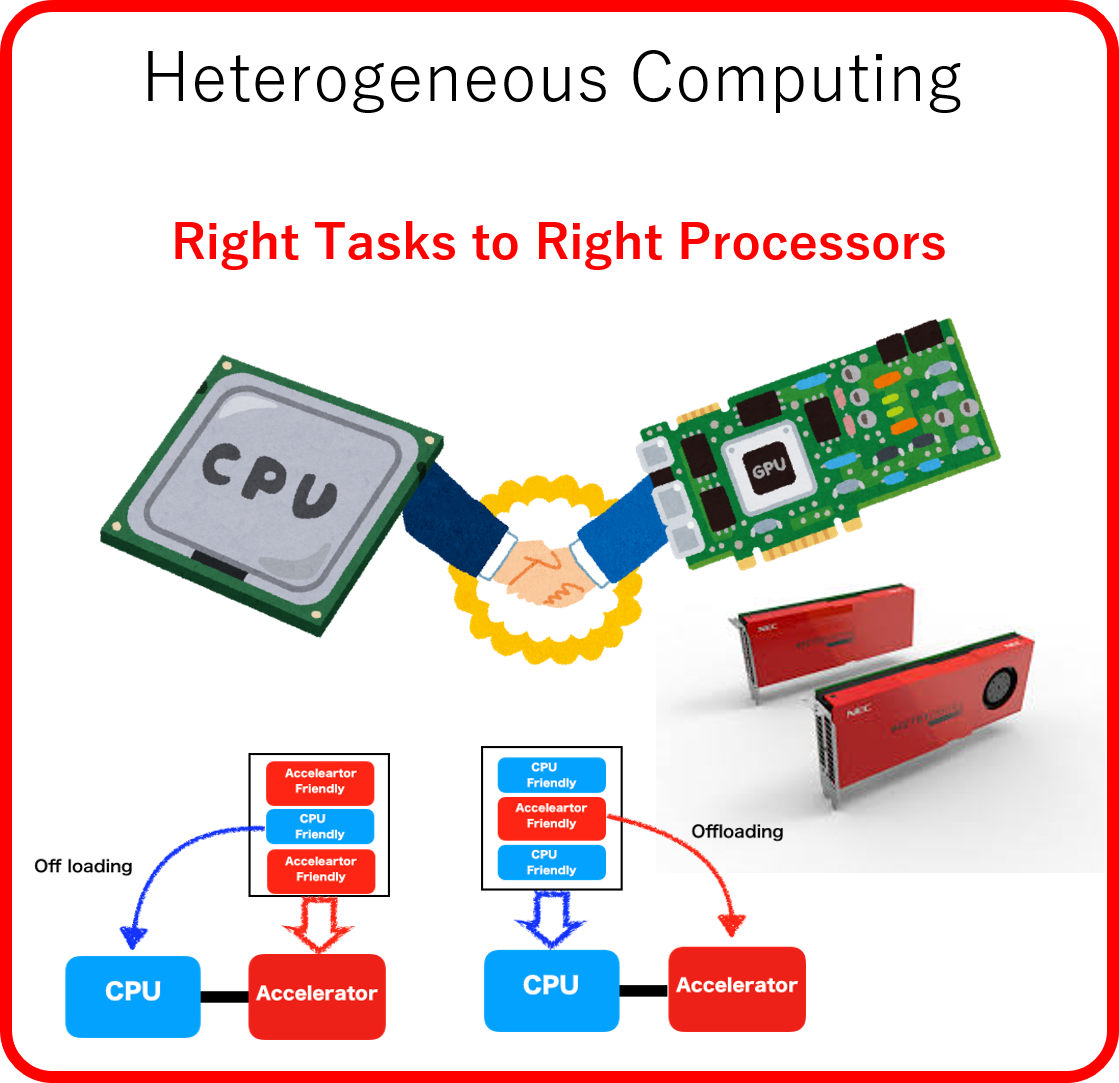
Heterogeneous Computing
Effective collaboration of different kinds of
processors
Many supercomputers in recent years have accelerators specialized for
scientific computation in addition to
the conventional general-purpose processors (CPUs). Representative accelerators are
Graphics Processing Units (GPUs) and Vector Engines (VEs). By using accelerators,
many applications can
obtain significant
performance improvement compared with just
using CPUs. Besides, since accelerators can achieve high energy efficiency,
accelerator computing will be
widespread and generalized even more in the future.
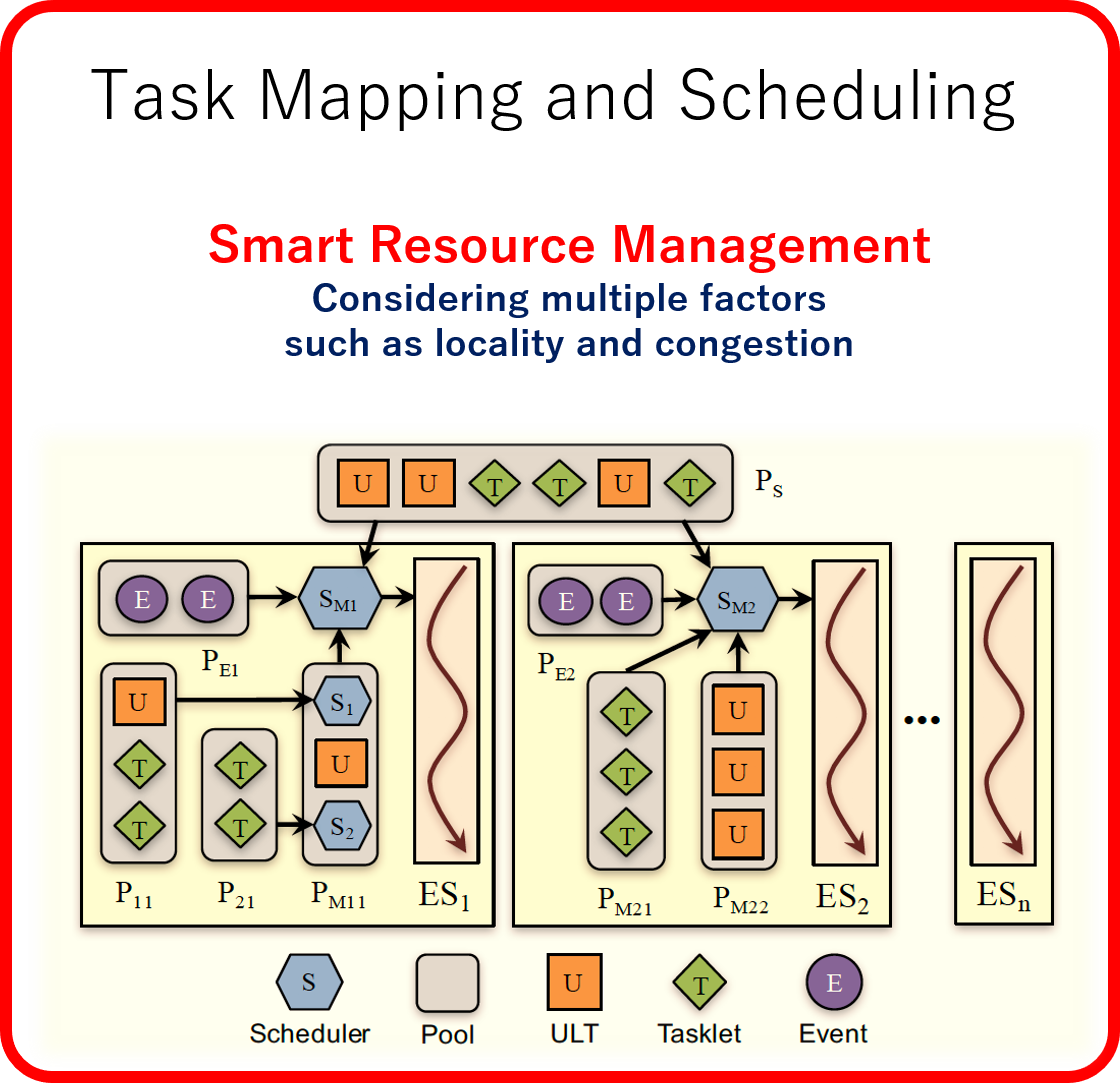
Task Mapping and Scheduling
Intelligent resource management is a key to achieve
high performance.
The mapping of tasks to processor cores, called task mapping, is crucial to achieving
scalable performance on multicore
processors. On modern NUMA (non-uniform memory access) systems, the memory
congestion problem could degrade the
performance more severely than the data locality problem because heavy congestion on
shared caches and memory
controllers could cause long latencies. Conventional work on task mapping mostly
focuses on improving the locality of
memory accesses. However, we showed that on modern NUMA systems,
maximizing the locality can degrade the
performance due to memory congestion. Therefore, we propose a task mapping method
that addresses the locality and the
memory congestion problems to improve the performance of parallel applications.
Tsunami Inudation Simulation
Predicting damage from a tsunami immediately after the earthquake
TWe established a new method of real-time tsunami inundation forecasting, damage estimation and mapping with use of advanced sensor networks and modern computing power. The method consists of fusion of real-time crustal deformation monitoring/fault model estimation, high-performance real-time tsunami propagation/inundation simulation with a vector supercomputer, and tsunami fragility curves for damage/loss estimation. The method has recently accomplished “10-10-10 challenge”, to complete tsunami source determination in 10 minutes, tsunami inundation modeling in 10 minutes with 10 m grid resolution.
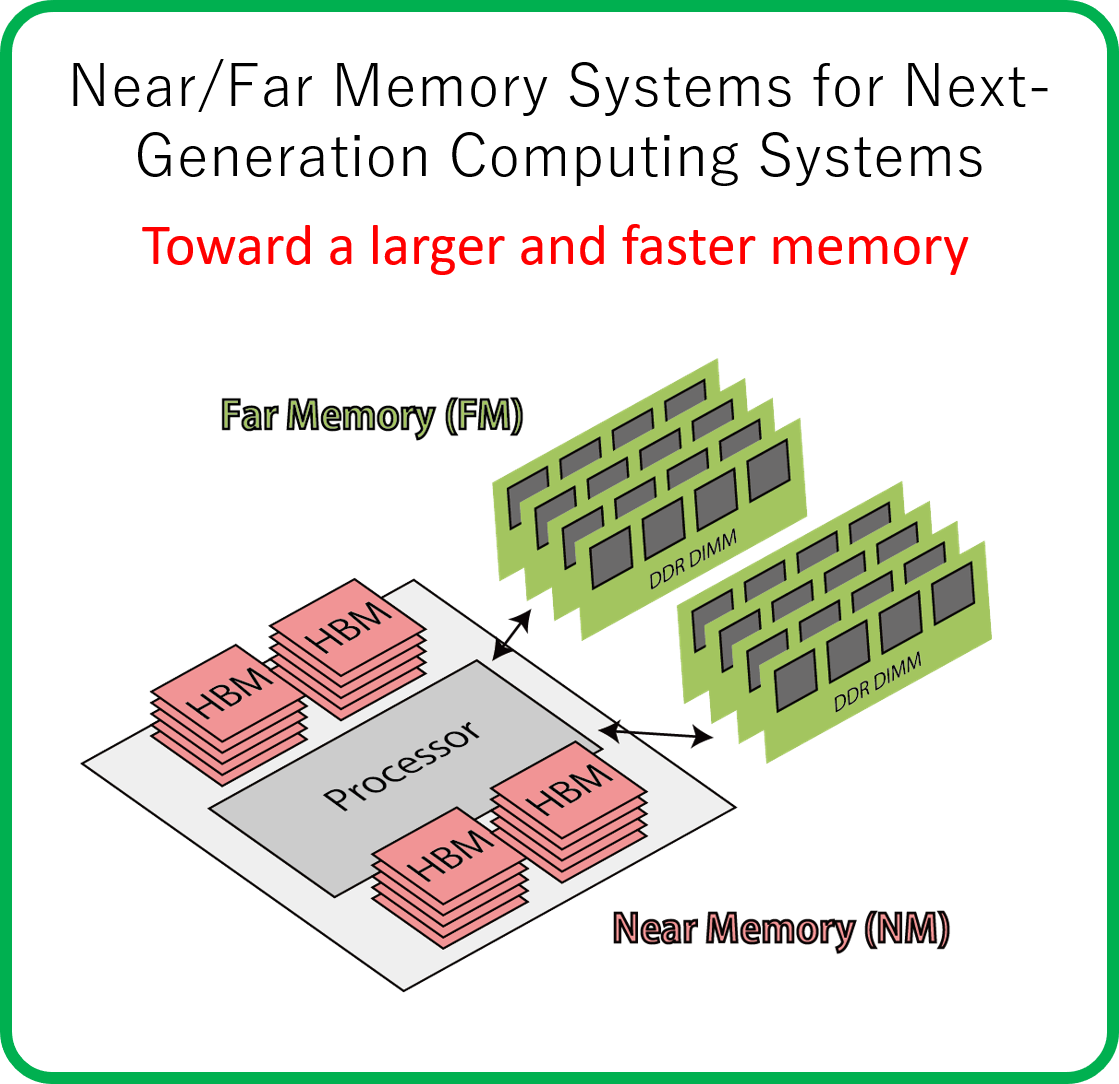
Memory Architecture Design
Integrating large and fast memories into a single system
A modern computer needs a memory system with a high performance and a large capacity. The goal of this research is to achieve a Near/Far memory system that consists of memory modules with different performances and capacities. Moreover, the system appropriately organizes the application data among these modules by data access characteristics.
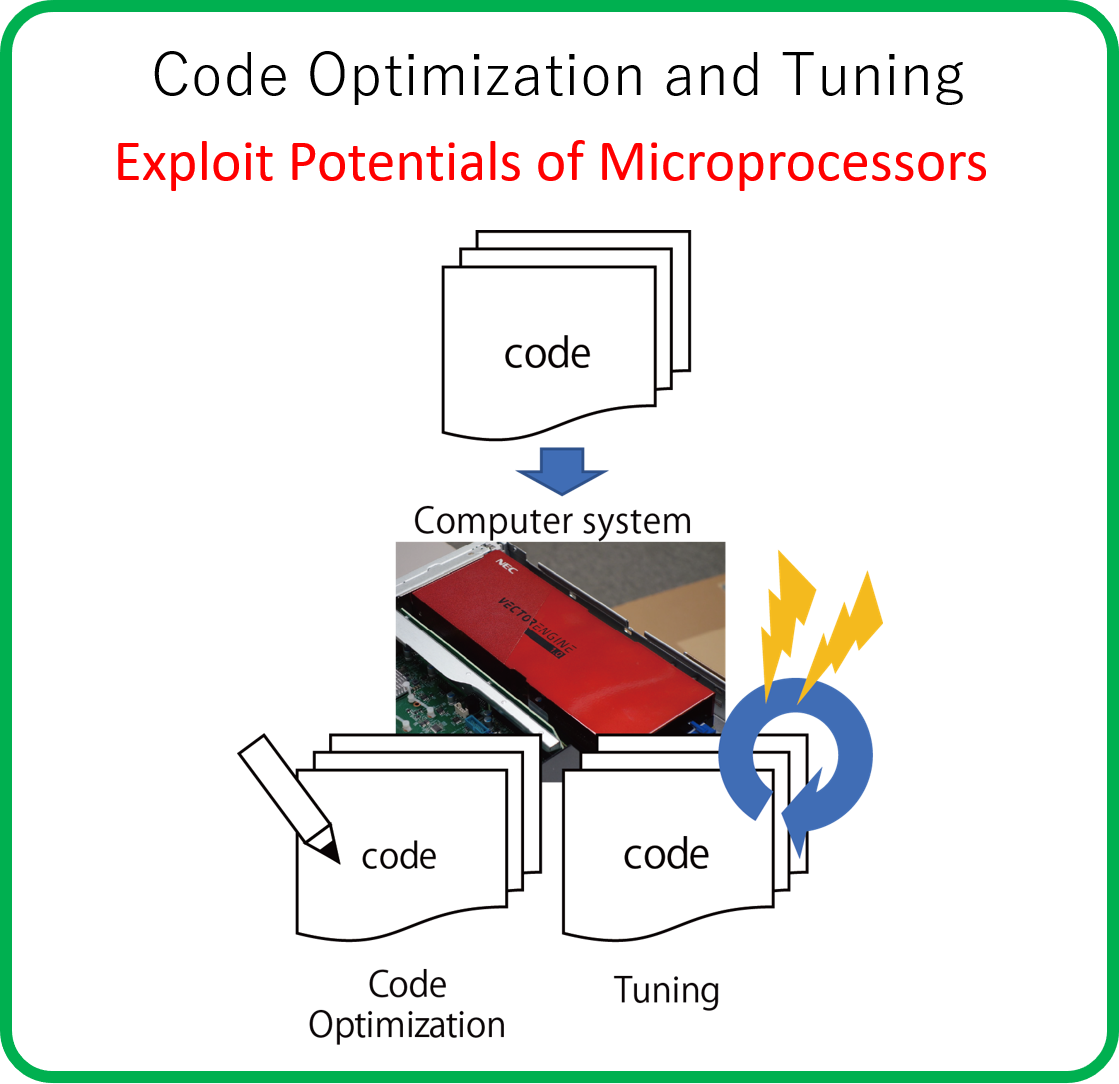
Code Optimization and Tuning
Making application codes suitable for a specific architecture.
Microprocessors increase diversity due to the trends in manufacturing technologies and applications. This research evaluates various latest microprocessors and, based on the evaluation results, adopts the applications to the microprocessors by optimizing and tuning the application codes to obtain the high performances.